Le PRIMERGY CX400 M1 de Fujitsu propose 4 nœuds serveur biprocesseurs demi-largeur et jusqu’à 24 disques dans un seul boîtier rack 2U.
Le gain de 50 % d’espace dans un rack par rapport aux serveurs rack standard offre une plus grande évolutivité.
La haute densité des serveurs améliore les performances par unité de rack (4 serveurs, 8 processeurs, 24 disques et 64 modules DIMM dans un châssis 2U).
C’est donc la plateforme idéale pour déployer Windows Server 2016, Hyper-V et Storage Spaces Direct, la solution hyper convergence de Microsoft
Le matériel :

4 baies pour serveurs demi-largeur CX2500 M2, 2 emplacements pour modules d’alimentation

Le PRIMERGY CX2550 M2 est un nœud serveur compact qui prend en charge la dernière famille de processeurs Intel® Xeon® E5-2600 v4, offrant une densité de calcul très élevée avec quatre serveurs indépendants dans un châssis 2U. L’idéal pour les applications d’informatique hautes performances, l’hébergement, les piles hyper-convergées ainsi que dans les environnements Big Data.



Dans notre configuration, chaque nœud possède 4 disques SSD entreprise Samsung SM863
(SSD SATA, 6 Gb/s, 240 GB, Mixed-use, hot-plug, 2.5-inch, enterprise, 3 DWPD)

Les prises de courant fournies son destinées à être branchées sur des PDU adaptées

Détails techniques
| Type de châssis | Châssis 2U pour rack 19 pouces |
|---|---|
| Poids | jusqu’à 40 kg |
| Baies avant | Unités de stockage : 6 disques 2,5″, 12 disques 2,5″, 24 disques 2,5″ (disque dur, SSD) |
| Baies arrière | 4 baies pour serveurs demi-largeur CX25x0 M1/M2,2 emplacements pour modules d’alimentation |
| Configuration des ventilateurs | 4 ventilateurs non hot-plug |
| Configuration de l’alimentation | 2 modules d’alimentation hot-plug |
| Boutons de commande | Bouton marche/arrêt,Bouton d’ID |
| Voyants d’état | Identification (bleu),Alimentation (vert) |
| Période de garantie | 3 ans |
| Type de garantie | Garantie sur site |
| Service recommandé | 7 j/7, 24 h/24, temps de réponse sur site : 4 h – Pour les sites hors EMEIA, veuillez contacter votre partenaire Fujitsu local. |
| Cycle de vie du service | 5 ans |
Installation:
Les serveurs étant équipés de carte de contrôle à distance iRMC (IRMC de 4ème génération) , j’ai pu utiliser ce moyen afin de déployer les 4 Windows Server 2016 Datacenter.
Je rappelle que malheureusement, S2D ( Storage Space Direct) n’est dispo que sur la version Datacenter …
Je ne décris pas en détail le déploiement des différents nœuds, mais vous trouvez la procédure ici : Solution hyperconvergée utilisant des espaces de stockage direct dans WindowsServer2016
Tous les serveur étant munis de 2 cartes ethernet 10 Gb et de 2 cartes 1 Gb, j’ai décidé d’utiliser les cartes 10 Gb pour le réseau de stockage, et les 1Gb pour le Vswitch des VM.
Les cartes 10 Gb ne sont ni RDMA ni IWARP, mais sont les cartes d’entrée de gamme Intel X540 (Ethernet Server Adapter Eth Ctrl 2x10GBase-T PCIe x8 X550-T2 LP).. Le switch utilisé est un DLINK DXS-1210-10TS qui m’a été gentiment prêté par Dlink . Il possède 8 ports 10Gb ethernet cuivre + 2 ports fibre 10 G. Je n’utiliserai que les ports cuivres reliés avec du catégorie 6a minimum.
Un test avec NTTCP entre deux serveurs permet de valider le débit: 1040 MB/s soit 8,32 Gb/s. Grâce au SMB 3.1.1 et à la présence des 2 cartes, nous pourrons compter sur une bande passante de 16,64 Gb/s par serveur.

Les test de performance:
Pour tester ce genre de plateforme Microsoft fournit un outil spécifique :VMFleet
C’ est une collection de scripts qui permet de déployer des machines virtuelles qui effectuent des E / S pour souligner le système de stockage sous-jacent, grâce a DiskSpd qui génére un profil d’IO .
Prérequis:
- Les Fichiers VMFleet de GitHub: https://github.com/Microsoft/diskspd
- Diskspd.exe qui est disponible sur http : // aka . ms / diskspd
- Un fichier VHDX fixe d’ au moins 20 Go avec Windows Server 2016 Core installé et le mot de passe du compte d’administrateur local défini.
Configuration VMFleet:
Pour déployer l’ensemble des VM, VMFleet a besoin de plusieurs volumes partagés par cluster (CSV) dans le cluster. Il faut créér un CSV par nœud ainsi qu’un autre CSV appelé Collect. Ce CSV stockera les scripts VMFleet, les drapeaux, les résultats et l’image master des VM.
- J’ai donc créé un CSV de 50 Go :
|
1 |
New-Volume -StoragePoolFriendlyName "S2D*" -FriendlyName Collect -FileSystem CSVFS_ReFS -Size 50GB |
- Puis 4 CSV portant le nom de chaque nœud pour stocker les VM de test:
|
1 |
Get-ClusterNode |% { New-Volume -StoragePoolFriendlyName "S2D*" -FriendlyName $_ -FileSystem CSVFS_ReFS -Size 250GB |
- Extraire le fichier ZIP avec les scripts VMFleet ( Fichiers VMFleet de GitHub: https://github.com/Microsoft/diskspd ) sur l’un des noeuds du cluster.
(Par exemple sur C: \VMFleet sur le premier nœud du cluster). - Exécutez le script install-vmfleet.ps1 . Cela créera la structure de dossier nécessaire sur le CSV « collect.
|
1 |
install-vmfleet.ps1 -source C:\VMFleet |
- Copiez le DISKSPD.exe sur C: \ ClusterStorage \ Collect \ Control \ Tools
- Copiez le modèle VHDX vers C: \ ClusterStorage \ Collect
- Exécutez le script update-csv.ps1 pour renommer les points de montage des volumes CSV et distribuer CSV même dans le cluster afin que chaque nœud soit le propriétaire d’un CSV qui porte son nom.
- Et maintenant créér l’ensemble des VM: j’ai donc décidé de créér 10 VM par hote, soit un total de 40 VM
|
1 |
create-vmfleet.ps1 -basevhd 'C:\ClusterStorage\Collect\gold.vhdx' -vms 40 -adminpass P@ssw0rd -co;nnectuser administrator -connectpass P@ssw0rd |
- Un fois les vm créées il est possible d’en modifier les caractéristiques car par défaut elles n’ont qu’un seul processeur et 1 Go de ram:
|
1 |
set-vmfleet.ps1 -ProcessorCount 2 -MemoryStartupBytes 4GB -MemoryMinimumBytes 4GB -MemoryMaximumBytes 4GB |
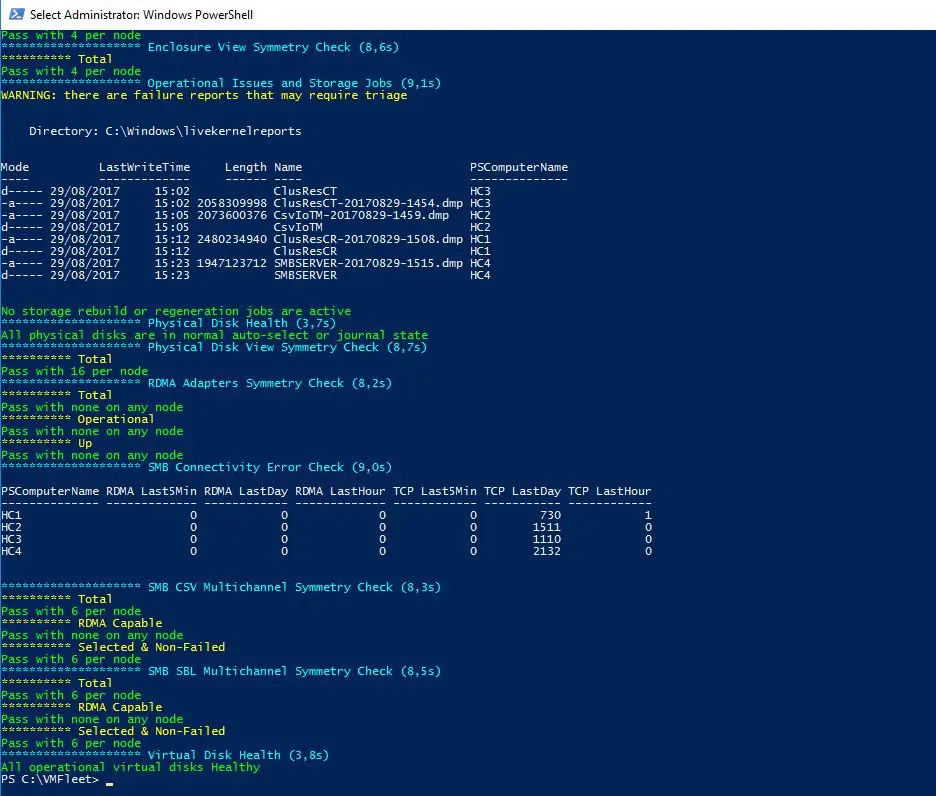
Avant de lancer le test il est recommandé de vérifier la santé du cluster ave un script fourni par VMFleet: test-clusterhealth.ps1
Exécution des tests:
Pour commencer un balayage, j’utilise le script Start-sweep.ps1. Ce script accepte les paramètres suivants. Ces paramètres sont transmis à DiskSpd pour exécuter le test.
- B: tailles de l’IO (KiB)
- T: nombres de threads
- W: poucentaged’écriture
- P: type d’acces (aléatoire: r, séquentiel: s, séquentiel interconnecté: si)
- Q: Profondeur de la file d’attente
- warm: durée de la montée en charge de pré-mesure (secondes)
- D: durée du test (secondes)
- Cool: durée du temps de décharge post-mesure (secondes)
Pour commencer , je lance le script suivant pour lancer un test de lecture à 100% bloc de 8Ko, 4 thread en accès aléatoire, et pour visualiser les résultats je lance le script watch-cluster.ps1:
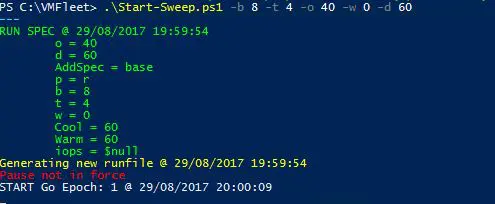
Un total de 740 000 IO par secondes 🙂

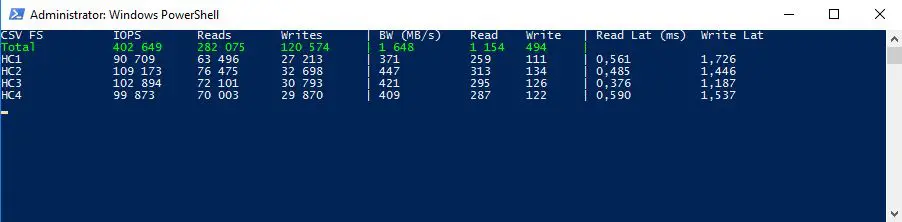
Maintenant quelque chose de plus réaliste avec un test 70R/30W qui est plus proche de ce que l’on retrouve sur les baie de stockage en production:
402 000 IO/s avec une latence inférieure a 2 ms
Cible CPU:
Le script sweep-cputarget.ps1 permet d’effectuer plusieurs tests afin d’extrapoler la charge CPU en fonction des IO.
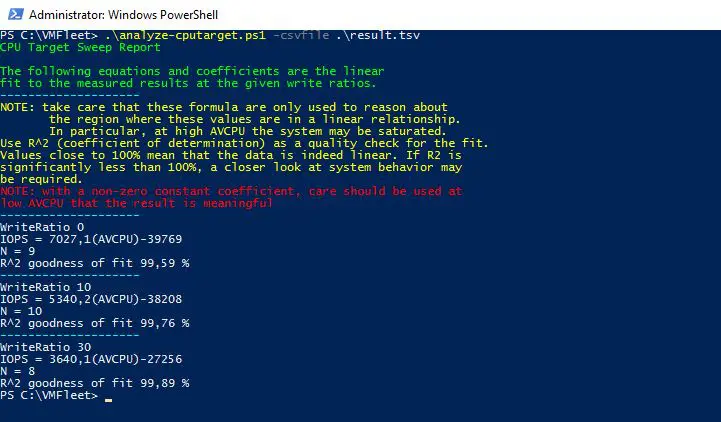
Le test est réalisé avec 0,10,30 % d’écrite. Il en résulte une formule qui par exemple pour 10 % d’écriture et une charge CPU de 50 % nous donne:
5340,2 * 50 -38208 = 228 802 IO/s
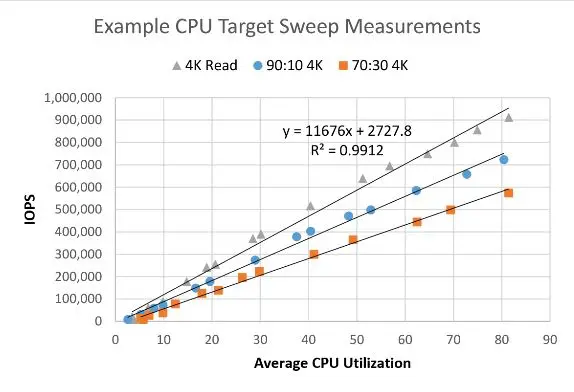
Cela permet en extrapolant toutes les valeurs d’avoir un tableau de ce type et d’avoir une bonne projection de la montée en charge:
Monitoring:
Il existe quelques solutions pour avoir un dashboard (5nine, starwind…) mais l’on peut aussi se construire quelque chose avec Telegraf et Grafana:
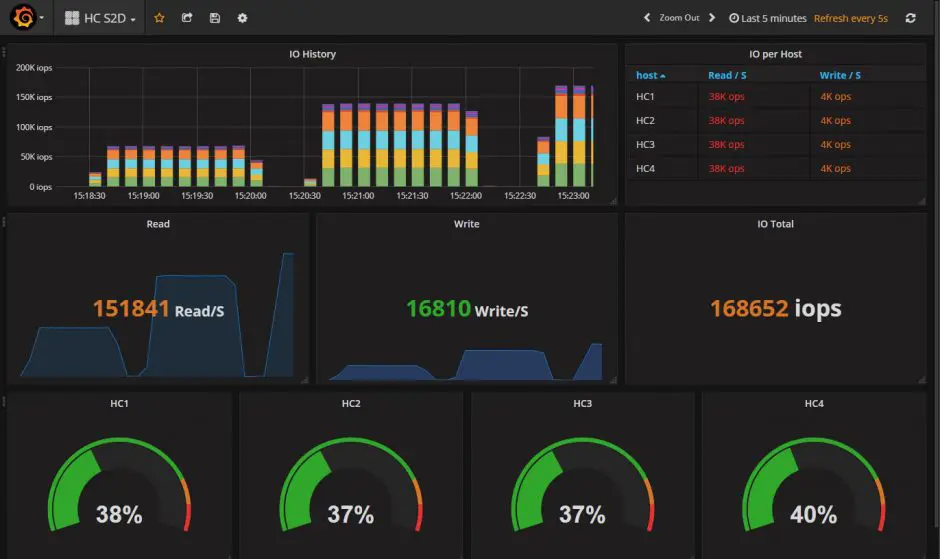
Conclusion:
Avec simplement 2U de hauteur, ce cluster composé de 4 nœuds et de 40 VM prouve que l’on peut se passer d’infrastructure SAN même si l’on a besoin de beaucoup d’IO.
Aujourd’hui peu d’infrastructures dans les datacenters privés peuvent se targuer de sortir 400 000 IO en 70/30. Et avec 6 SSD par node je pense que les 1 millions d’IO auraient été atteints !!!
Prix de la configuration ?? Autour de 40 K€ licences Windows 2016 DATACENTER incluses.
Si cette configuration vous a convaincu, n’hésitez pas a me contacter !